0 认识爬虫
笔记
什么是爬虫?
爬虫是什么?
了解浏览器的工作原理?
爬虫能做很多事,能做商业分析,也能做生活助手,比如:分析北京近两年二手房成交均价是多少?深圳的Python工程师平均薪资是多少?北京哪家餐厅粤菜最好吃?等等。
这是个人利用爬虫所做到的事情,而公司,同样可以利用爬虫来实现巨大的商业价值。比如你所熟悉的搜索引擎——百度和谷歌,它们的核心技术之一也是爬虫,而且是超级爬虫。
爬虫还让这些搜索巨头有机会朝着人工智能的未来迈进,因为人工智能的发展离不开海量的数据。而每天使用这些搜索网站的用户都是数以亿计的,产生的数据自然也是难以计量的。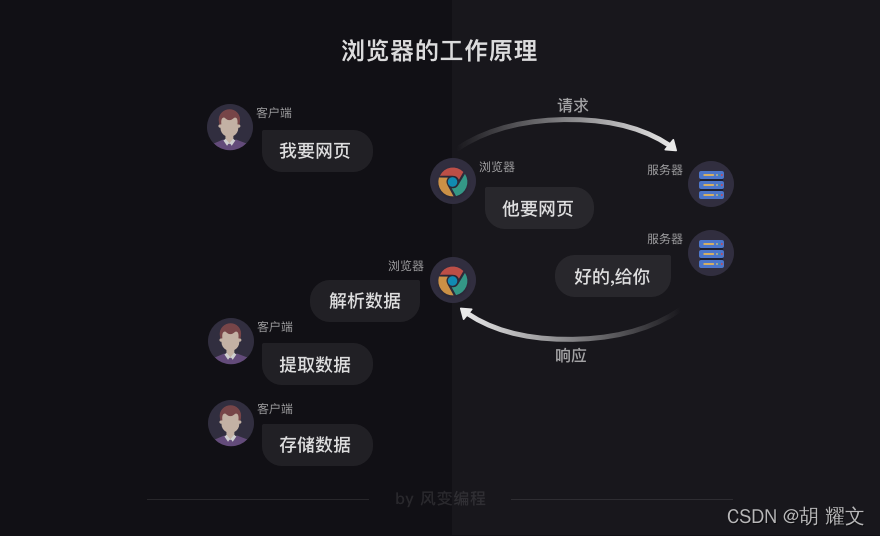
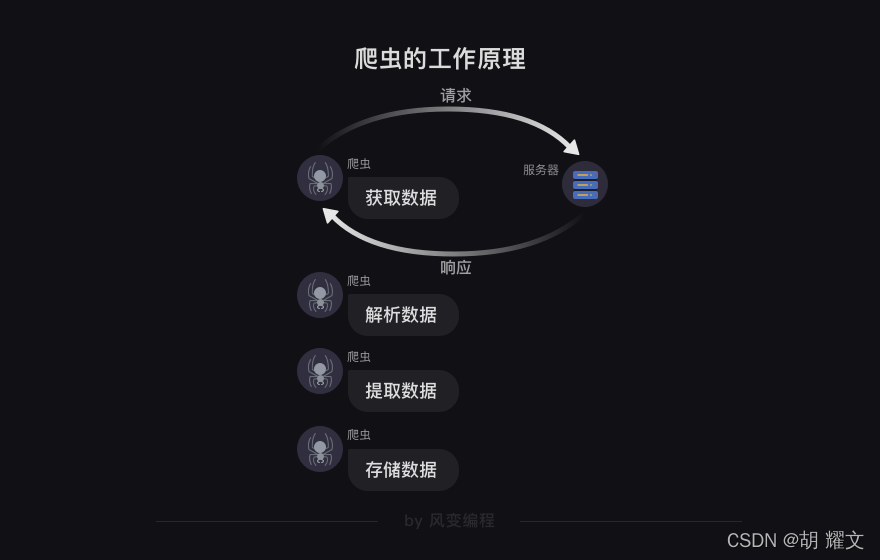
第0步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求然后返回数据
第1步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式。
第2步:提取数据。爬虫程序再从中提取出我们需要的数据。
第3步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
requests库可以帮我们下载网页源代码、文本、图片,甚至是音频。其实,“下载”本质上是向服务器发送请求并得到响应。
Python是一门面向对象编程的语言,而在爬虫中,理解数据是什么对象是非常、特别、以及极其重要的一件事。因为只有知道了数据是什么对象,我们才知道对象有什么属性和方法可供我们操作。
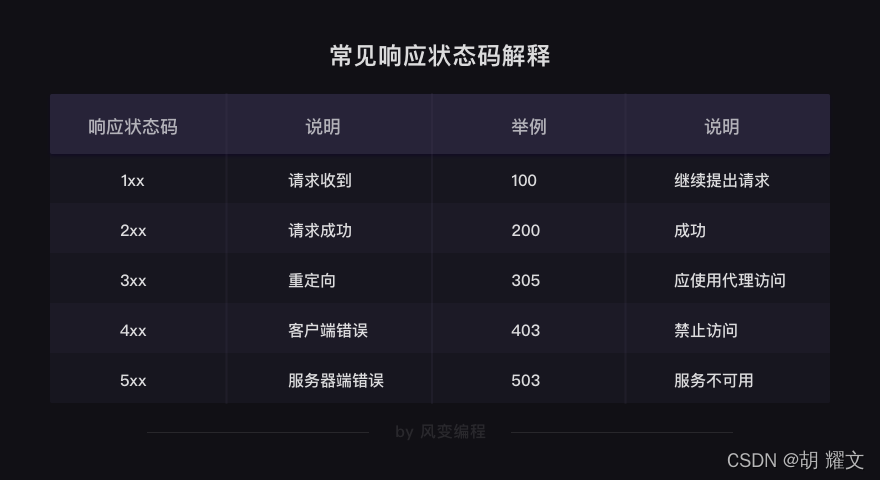
解析文本为什么会出现一段乱码呢?
事情是这样的:首先,目标数据本身有它的编码类型,
获取目标数据后要知道相应的编码类型才能正确解码。
编解码要共享同一种编码类型,就像你给我传纸条用的编码方式如果是“拼音”,我收到后就要拼“拼音”来理解语意——若我以为是“英语”,去查英语字典,那必然看不懂你说了什么。
Python关于requests.exceptions.ProxyError异常的问题
把VPN关掉就好了
服务器其实就是一个超级电脑,拥有这个服务器的公司,对爬虫其实也有明确的态度。
通常情况下,服务器不太会在意小爬虫,但是,服务器会拒绝频率很高的大型爬虫和恶意爬虫,因为这会给服务器带来极大的压力或伤害。
不过,服务器在通常情况下,对搜索引擎是欢迎的态度(刚刚讲过,谷歌和百度的核心技术之一就是爬虫)。当然,这是有条件的,通常这些条件会写在robots协议里。
robots协议是互联网爬虫的一项公认的道德规范,它的全称是“网络爬虫排除标准”(robots exclusion protocol),这个协议用来告诉爬虫,哪些页面是可以抓取的,哪些不可以。
我们使用robots协议的场景通常是:看到想获取的内容后,检查一下网站是否允许爬取。因此我们只需要能找到、简单读懂robots协议就足够了。
域名中会藏着网站的国籍或功能领域等信息,那么.cn,.com,.gov结尾的域名分别代表了什么?
来看一个实例:我们截取了一部分淘宝的robots协议 ( http://www.taobao.com/robots.txt)。在截取的部分,可以看到淘宝对百度和谷歌这两个爬虫的访问规定,以及对其它爬虫的规定。
1 | User-agent: Baiduspiderz # 百度爬虫 |
可以看出robots协议是“分段”的吗?每个段落都含有以下两种字段:一种是User-agent:,另一种是Allow:或Disallow:。
User-agent表示的是爬虫类型,上面的示例代码注释了“百度爬虫”和“谷歌爬虫”,我们自己写的爬虫一般要看User-Agent: ,指向所有未被明确提及的爬虫。
Allow代表允许被访问,Disallow代表禁止被访问。字段对应的值都含有路径分隔符/,限制了哪些或哪一层目录的内容是允许或者禁止被访问的。可以对比上述百度爬虫Disallow: /product/和谷歌爬虫Allow: /product的注释行理解一下。
比如淘宝禁止其他爬虫访问所有页面,也就是说,我们自己写的爬虫不被欢迎爬取www.taobao.com域名下的任何网页。
有趣的是,淘宝限制了百度对产品页面的爬虫,却允许谷歌访问。
所以,当你在百度搜索“淘宝网”时,会看到下图的这两行小字。
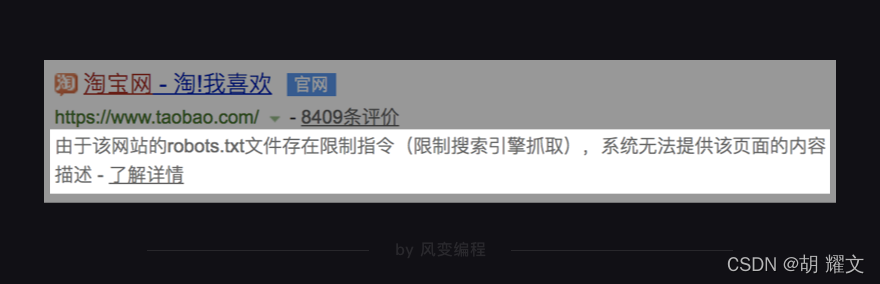
因为百度很好地遵守了淘宝网的robots.txt协议,自然,你在百度中也查不到淘宝网的具体商品信息了。
互联网并非法外之地,和爬虫相关的法律也在建立和完善之中,目前通用的伦理规范就是robots协议,我们在爬取网络中的信息时,应该有意识地去遵守这个协议。
网站的服务器被爬虫爬得多了,也会受到较大的压力,因此,各大网站也会做一些反爬虫的措施。不过呢,有反爬虫,也就有相应的反反爬虫
爬虫就像是核技术,人们可以利用它去做有用的事,也能利用它去搞破坏。
恶意消耗别人的服务器资源,是一件不道德的事,恶意爬取一些不被允许的数据,还可能会引起严重的法律后果。
工具在你手中,如何利用它是你的选择。当你在爬取网站数据的时候,别忘了先看看网站的robots协议是否允许你去爬取。
同时,限制好爬虫的速度,对提供数据的服务器心存感谢,避免给它造成太大压力,维持良好的互联网秩序,也是我们该做的事。
代码
1 | import requests |
1 | import requests |





