空气污染预测
摘要
作者:胡耀文
本文用北京2010年到2014年气压风向雨雪量等相关物理量的数据集,用LSTM做模型优化,来预测PM2.5浓度。
目前均方差在34左右,还有优化空间。后续会爬取广州的相关天气信息,来预测广州的空气污染程度。
第一,数据集
数据集是kaggle上找的,是北京2010年1月1日到2014年12月31日的数据
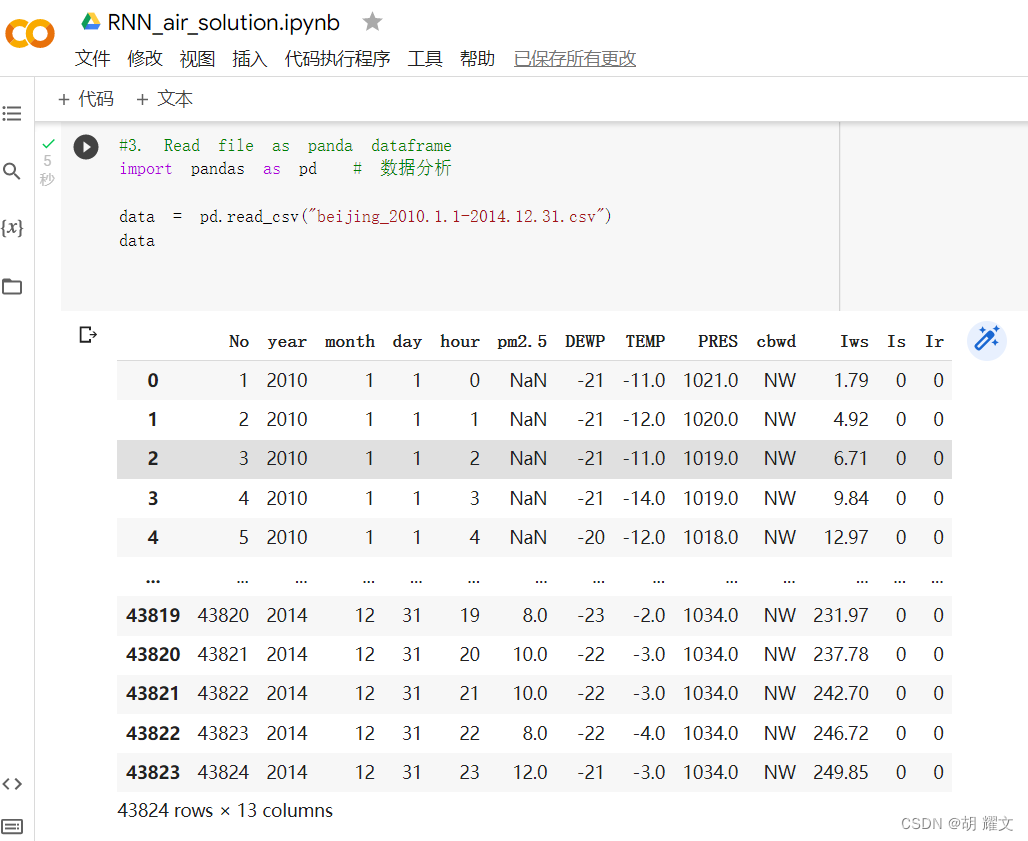
No是编号
year是年
month是月
day是日
hour是小时
PM2.5是预测值
DEWP是露点
TEMP是温度
PRES是大气压
cbwd是风向
lws是风速
Is是累积雨量
lr是累计雪量
每隔一小时就会采取一次数据
数据预处理
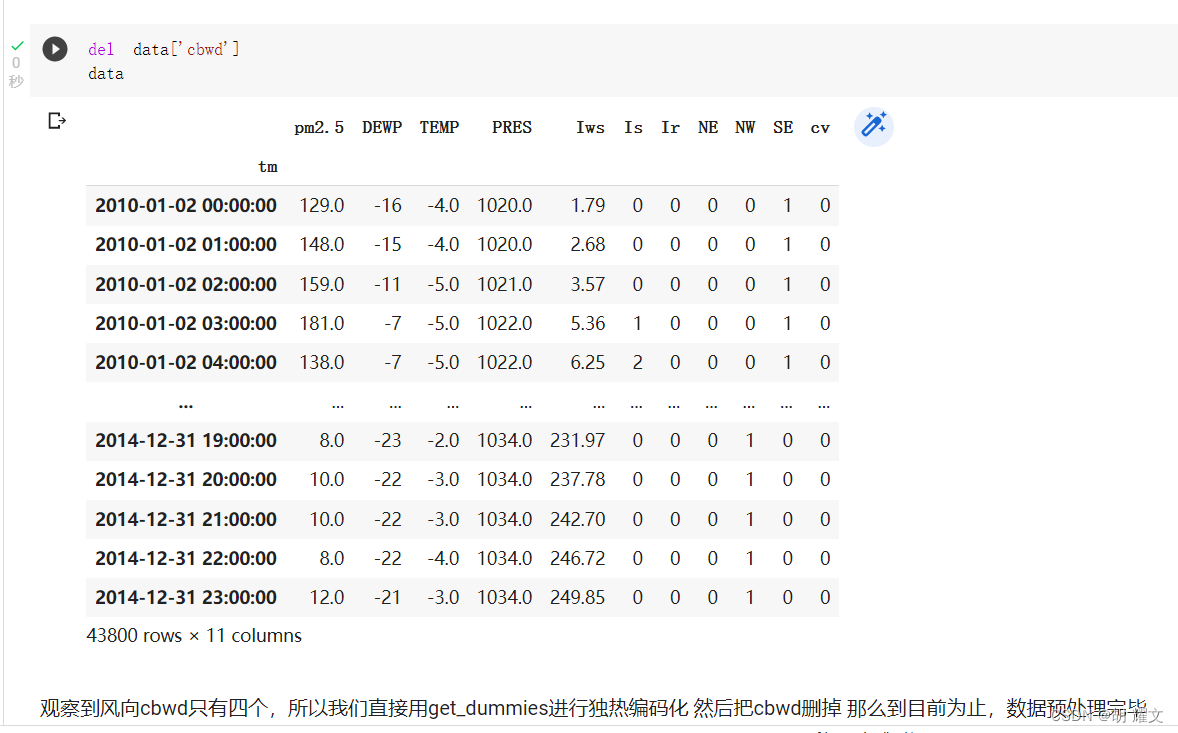
对NAN空值如果删掉的话会影响数据集的序列结构,所以这里采取前向填充
删掉编号,将年月日时用datetime压成一维作为唯一索引
风向有4个,用独热编码处理,从而删掉风向cbwd这一特征
至此,总计11个特征,用这11个特征来作为预测指标
策略采取
预测的时候,由于选择过早的数据或者过少的数据都是不对的
比如,仅仅用今天这一天的数据来预测明天的值是不恰的
或者用前一个月的值来预测明天的值也是过于浪费
用前一个星期的值就差不多了
在这里,我用了前五天的数据来预测第六天第24h的数据
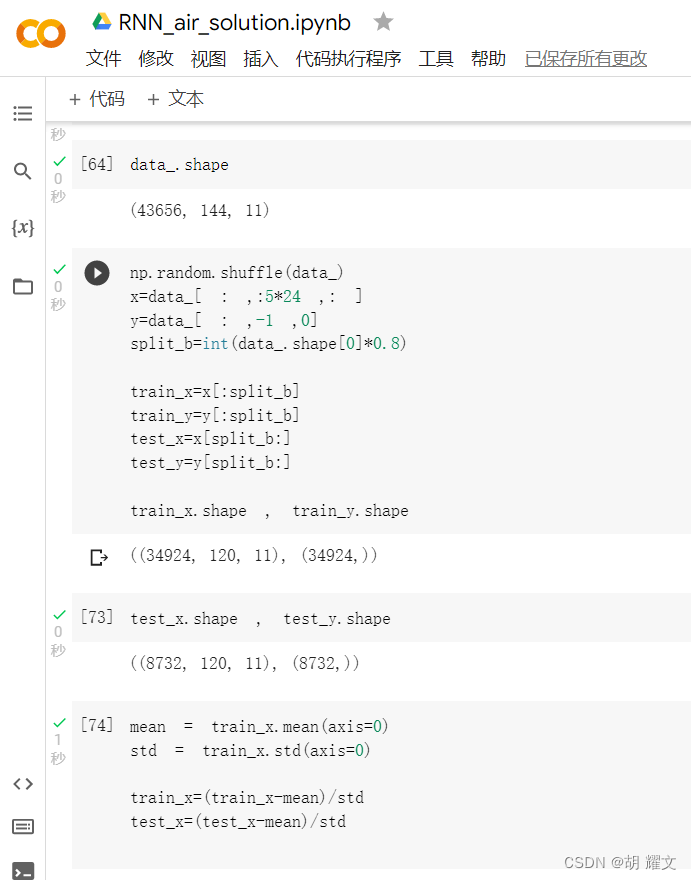
总数据集的百分之80作为训练数据,百分之20作为测试数据
至此,数据集部分处理完毕,
现在让我们看看要预测的PM2.5长啥样
下图是最后1000组PM2.5的数据
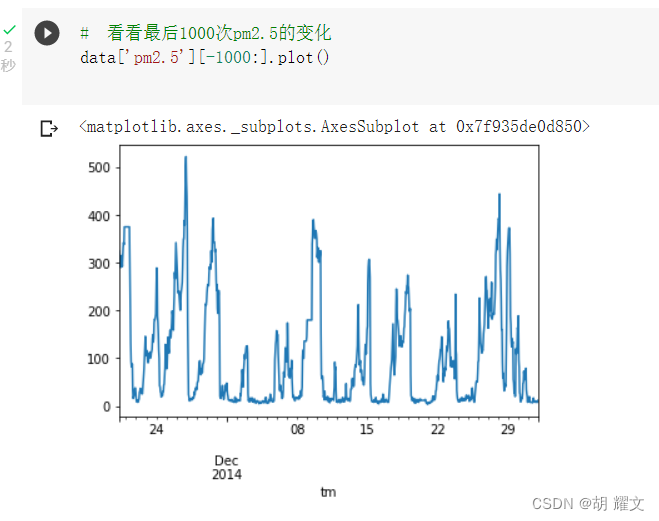
(emm如果你在北京为了肺好,建议昼伏夜出hhh~~
第二,模型训练,传统卷积和LSTM的比较
这是最简单的卷积层

50epoch之后总差值大于在5000,均方差大约在52左右
接下来看看LSTM
我在看官方文档的时候抄错好几次reduceLROnPlateau!!!!然后很莫名其妙的报了好多错
看来以后还是直接copy文档
我没记错的话LSTM特别的一个地方就是输入到输出这个过程会产生一组序列,叫中间状态,参与下一轮的输入到输出的计算
然后循环产生输出
这种特殊的运算结构让它特别擅长捕捉时间变化的趋势,比如对于星期一这样的数据,星期二会变成这样,对于星期二这样的数据,星期三会变成这样,……..,进而对星期六的数据进行较为精准的预测
我的理解就是:
如果这种时间戳的相对关系是对于要预测的指标是存在某种关系的话,那么LSTM在预测时会把这层关系计算进去,
在同等方法里面会很有优势,但如果根本不存在这种关系的话,就会出现“用了等于没用”的情况,
所以针对不同情况,要搭配不同的模型去计算,去预测,
这也是为什么人工智能行业一直在更迅捷的发展,
因为对于某种特定情况,可能目前为止没有哪一种模型更为契合,那么你就要“设计”一种方法,一种计算方法,
如果跑出来的结果比T0要好,那么你就是新的T0了哈哈
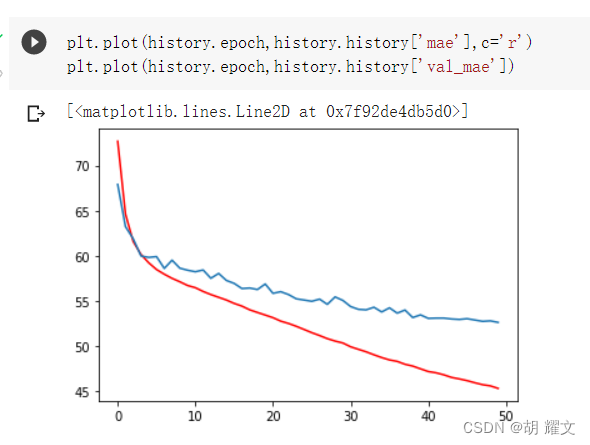
下图是开50epoch的时候跑出来的结果:
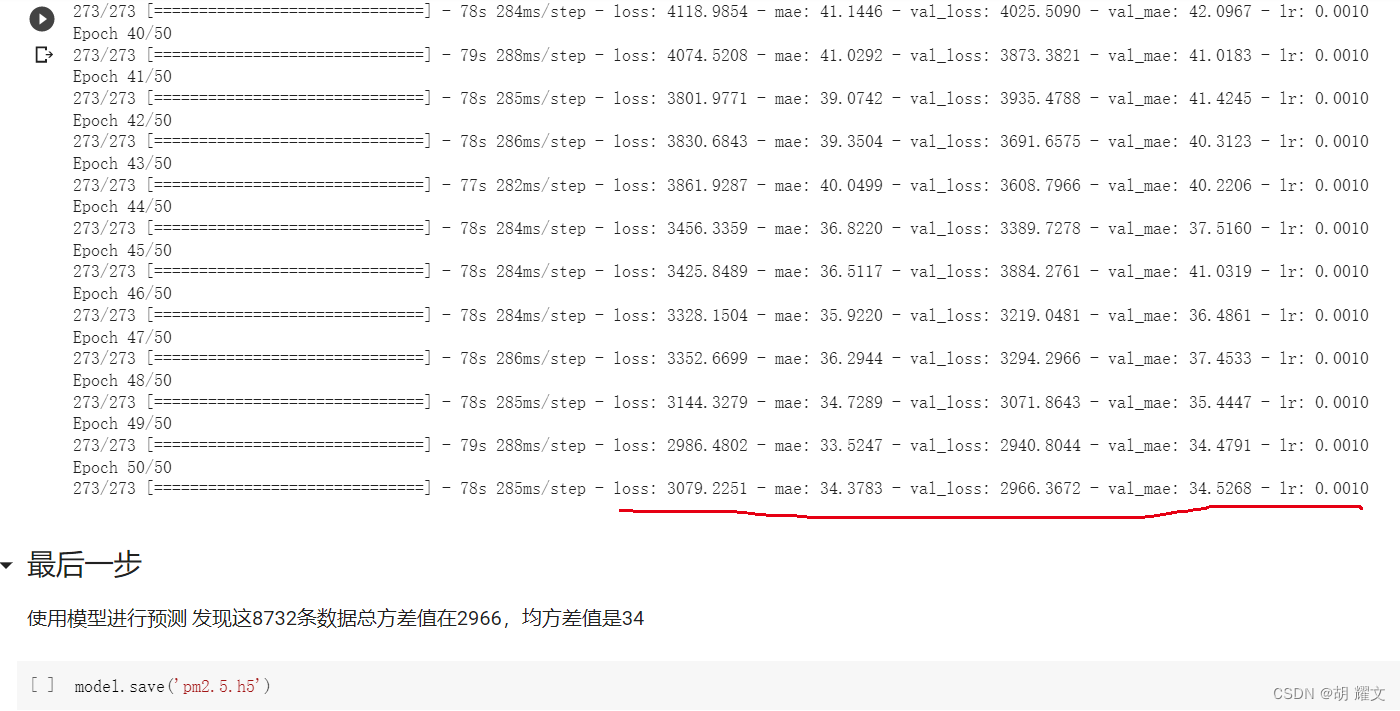
最后发现总方差在2966,均方差在34,从结果来看确实更好一点
LSTM使用的时候有两个点要注意一下:
- LSTM网络接受的是三维数据(batch,时间观测,特征)
- 堆叠LSTM网络,需要设置return_sequences=True,意思是对每个序列预测结果进行输出
第三,模型评价,多组数据预测和单组数据预测
多组数据预测,可以直接用那把百分之20的test_x
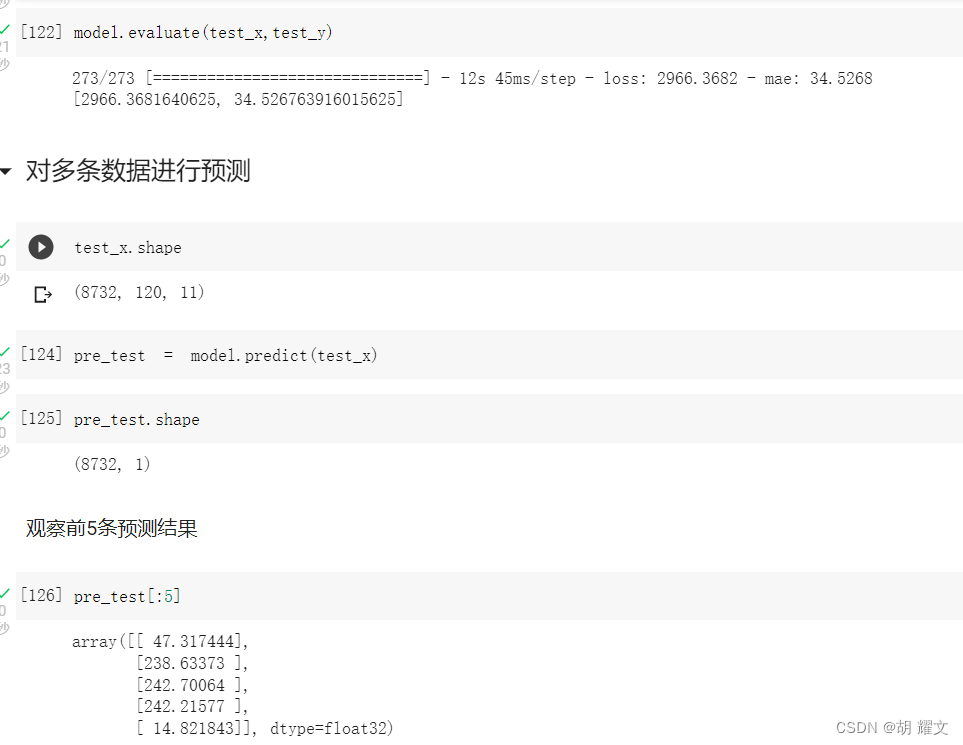
最后发现这8732条数据总方差在2966,均方差在34,
对单组数据进行预测
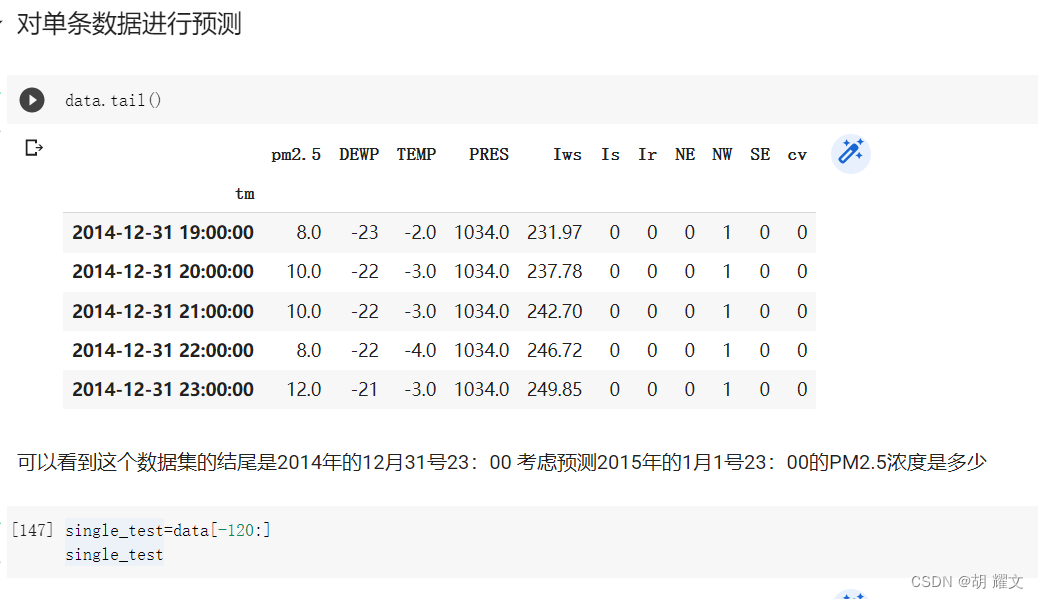
我们用最后的数据来预测2015年1月1日23时的情况
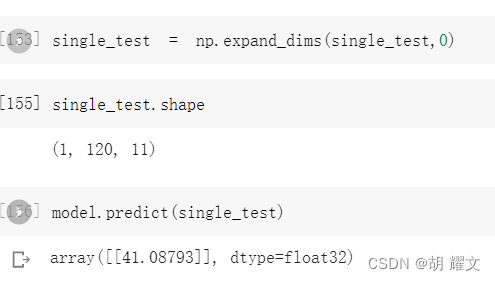
跑出来的结果是41
我们现在去官网查看北京历史空气污染数据
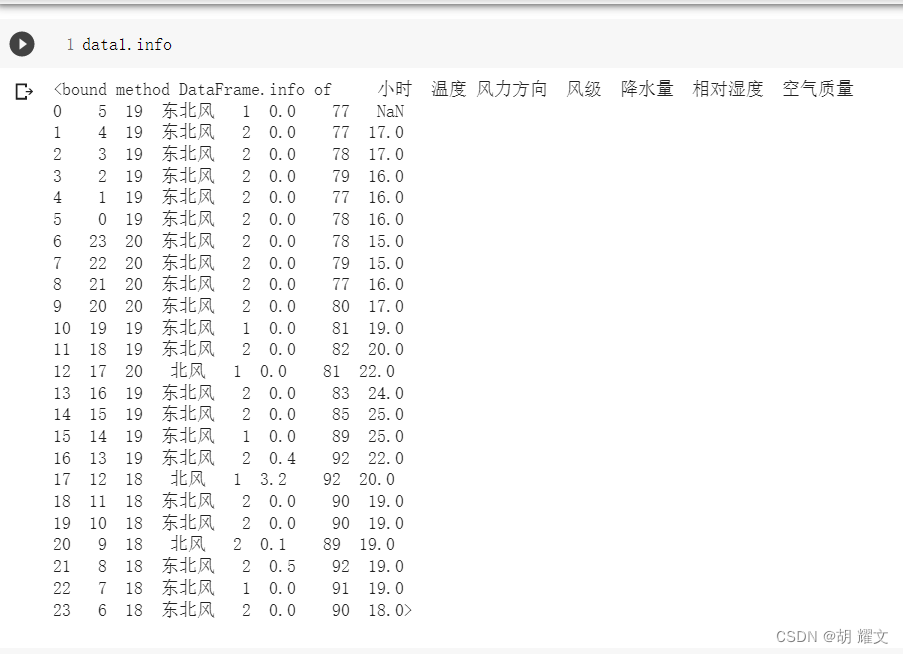
这里的数据是一整天的平均PM2.5浓度
2015年1月1日 平均浓度是41
2015年1月2日 平均浓度是51
预测1月1日23时的浓度时41
差值较小,跑出来的模型灰常ojbk!
第四,广州天气情况的爬取
只写了一点点,
爬取中国气象网
http://www.weather.com.cn/weather1d/101280101.shtml
上面这个网址是广东的天气信息
下面是爬取到当天24h的信息
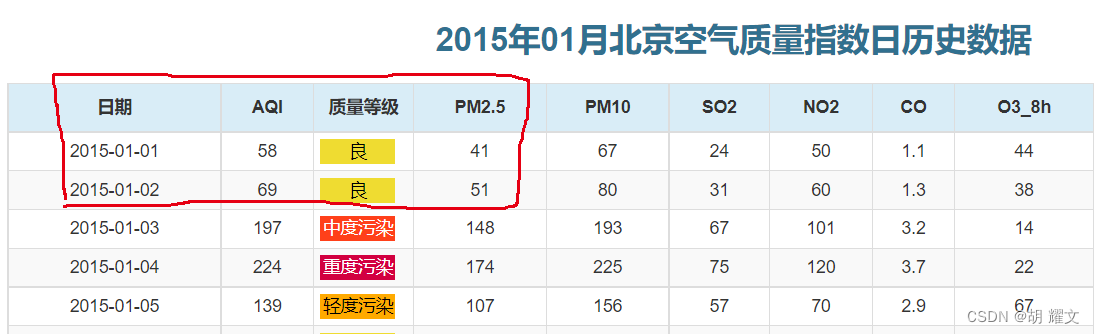
大约18,19摄氏度这样子,今天看看这个中国气象网有没有骗人。
第五,总结与思考
只要有相关特征,对某一指标的预测都可以用LSTM网络,都是ok的,
很多小tips都是在当前所学上进行一个小的拓展,
比如我在学openvino的时候,看人脸骨骼关键点检测,用这个东西你可以针对某些特定的关节点进行讨论
来完成一些奇奇怪怪的检测,比如看这个人有没有张嘴,或者看这个人眼睛有没有闭上,然后美其名曰:
人类公共场所喧哗检测,网课是否打瞌睡智能检测……
这些都是比较初级的,更高级一点的就是表情检测,导入某些表情参数,通过对人脸的识别判断是angry还是happy还是sad
等等。
回到这个空气污染预测,其实是这些指标能够较为充分的描述和概括PM2.5这个指标,所以有了比较好的预测结果,
预测气温,预测天气,预测空气湿度也是同样的道理,比如说如果是空气湿度,先去百度、知网找一找相关论文,看
空气湿度跟哪些因素有关,然后找一找网上有没有现成数据集,没有的话要去哪里爬取
整合成数据集然后进行特征提取训练……巴拉巴拉一大堆,然后你的一个小项目就水完了。
但很多时候不是一帆风顺的
在写的时候难免会遇到很多坑点
比如新版本有一些奇奇怪怪的错误,你去stack overflow搜的时候看到 “I also meet this problem,
I think what is about the upgrade , I had send email to them but they didnt give me a feedback”
那才是最最崩溃的。
kaggle与colab的区别
这次的全部代码我都是用colab敲的,自从升级成win11之后,我本地搭建的jupyter notebook跑一点点就宕机了,
昨晚第一次使用colab,给我的感觉就是白嫖真的香!很简约风,免费版的算力只有一般CPU的两倍,付费版的能达到6.5倍
要搭梯子,好不好用取决于你的梯子OK不OK,数据集的话不像kaggle那样自己弄了个dataset平台,很轻量级,
当然要用的话也可以用kaggle提供的API下载。
kaggle的话貌似不用搭梯子,里面有很多现成的数据集可以使用,这一点比colab方便很多,功能比较全更像是一个小型github
唯一的痛点就是要注册,而且真的很麻烦,我当时注册的时候反正就一直verify不成功,网上也没有好的解决方案,然后发邮件
过了十几个小时这样子那边 i am sorry to trouble 巴拉巴拉一大堆,反正终于ok终于注册成功了!
如果有更高追求的话,可以没有colab但不能没有kaggle,还是建议两边都去弄一个号。
最后代码挂在github上,题解报告也挂在了博客里,需要可自取



